





引言
随着互联网的快速发展,实时数据在前端展示的需求日益增长。爬虫作为一种获取网络数据的重要手段,能够帮助我们实时抓取网站上的数据,并将其传输到前端进行展示。本文将探讨如何将爬虫实时数据传输到前端,实现数据的实时更新和展示。
爬虫技术概述
爬虫(Spider)是一种自动化程序,用于从互联网上抓取信息。它通过模拟浏览器行为,按照一定的规则从网页中提取数据。常见的爬虫技术包括网络爬虫、深度爬虫、分布式爬虫等。在选择爬虫技术时,需要考虑数据抓取的规模、实时性、准确性等因素。
爬虫数据传输到前端的方案
将爬虫实时数据传输到前端,主要可以通过以下几种方案实现:
1. 客户端定时请求
前端页面定时向爬虫服务器发送请求,服务器返回最新的数据。这种方式简单易实现,但实时性较差,无法满足高频率的数据更新需求。
2. WebSocket协议
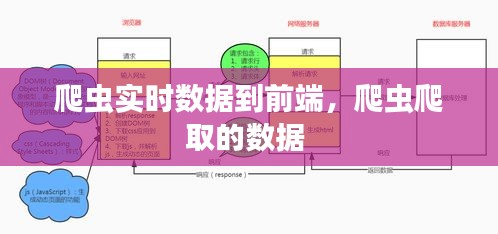
WebSocket协议提供了一种全双工通信方式,可以实现前端与服务器之间的实时数据传输。爬虫服务器将实时数据推送到前端,前端通过WebSocket连接接收数据。这种方式实时性高,但需要服务器端支持WebSocket协议。
3. Server-Sent Events (SSE)
Server-Sent Events (SSE) 是一种服务器向客户端推送数据的技术。爬虫服务器将实时数据以事件的形式发送给前端,前端通过监听这些事件来更新页面。这种方式简单易用,但实时性相对较低,且不支持大规模数据传输。
4. RESTful API + AJAX
爬虫服务器提供RESTful API接口,前端通过AJAX定时请求接口获取最新数据。这种方式灵活性好,但实时性较差,且需要前端不断发送请求来获取数据。
实现爬虫实时数据到前端的步骤
以下是实现爬虫实时数据到前端的基本步骤:
1. 设计爬虫程序
根据需求设计爬虫程序,确定爬取目标网站、数据格式、抓取频率等参数。
2. 数据存储
将爬取到的数据存储在数据库或缓存中,以便后续处理和传输。
3. 选择数据传输方案
根据实际需求选择合适的数据传输方案,如WebSocket、SSE等。
4. 实现数据传输
根据选定的方案,实现数据从服务器到前端的传输。例如,使用WebSocket协议时,需要实现WebSocket服务端和客户端的通信逻辑。
5. 前端页面展示
在前端页面中使用JavaScript等技术,根据接收到的数据实时更新页面内容。
总结
将爬虫实时数据传输到前端,是当前互联网应用中常见的需求。通过选择合适的数据传输方案和实现技术,可以实现数据的实时更新和展示。本文介绍了爬虫技术概述、数据传输方案以及实现步骤,希望对读者有所帮助。
转载请注明来自瑞丽市段聪兰食品店,本文标题:《爬虫实时数据到前端,爬虫爬取的数据 》






 滇ICP备2023011059号-1
滇ICP备2023011059号-1