






引言
随着大数据时代的到来,实时计算在各个领域都变得越来越重要。数据库作为存储和管理数据的核心,实时计算能力的高低直接影响到数据分析和决策的效率。本文将探讨如何实现数据库的实时计算,包括技术选型、架构设计以及具体实现方法。
技术选型
实现数据库实时计算,首先需要选择合适的技术。以下是一些常见的技术选型:
流处理框架:如Apache Kafka、Apache Flink等,能够处理高并发的实时数据流。
内存数据库:如Redis、Memcached等,具有高性能的读写能力,适合实时计算。
实时查询引擎:如Elasticsearch、Drill等,能够对实时数据进行快速查询和分析。
分布式计算框架:如Apache Hadoop、Apache Spark等,能够处理大规模的实时数据。
在选择技术时,需要考虑以下因素:
数据量:根据数据量的大小选择合适的技术。
实时性要求:根据实时性要求选择适合的延迟和吞吐量。

易用性:考虑技术的易用性和维护成本。
架构设计
实现数据库实时计算的架构设计主要包括以下几个部分:
数据采集层:负责从各种数据源采集数据,如日志、传感器、业务系统等。
数据存储层:负责存储实时数据,可以使用内存数据库、分布式数据库或流处理框架。
数据处理层:负责对实时数据进行处理和分析,可以使用流处理框架、实时查询引擎或分布式计算框架。
数据展示层:负责将处理后的数据以可视化的形式展示给用户。
以下是一个简单的架构示例:
具体实现方法
以下是实现数据库实时计算的几个具体步骤:
数据采集:使用数据采集工具(如Flume、Logstash等)从各个数据源采集数据。
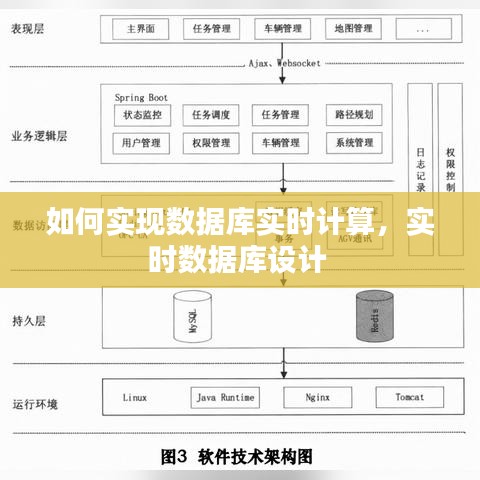
数据存储:将采集到的数据存储到内存数据库或流处理框架中。
数据处理:使用流处理框架(如Apache Kafka、Apache Flink等)对实时数据进行处理和分析。
数据展示:使用实时查询引擎(如Elasticsearch、Drill等)对处理后的数据进行查询和分析,并将结果展示给用户。
以下是一个具体的实现示例:
使用Apache Kafka作为数据采集和存储层,实现数据的实时传输和存储。
使用Apache Flink作为数据处理层,对实时数据进行计算和分析。
使用Elasticsearch作为数据展示层,对处理后的数据进行查询和分析。
总结
实现数据库实时计算需要综合考虑技术选型、架构设计和具体实现方法。通过合理的技术选型和架构设计,可以有效地提高数据库的实时计算能力,为用户提供实时、准确的数据分析和决策支持。随着技术的不断发展,数据库实时计算将会在各个领域发挥越来越重要的作用。
转载请注明来自瑞丽市段聪兰食品店,本文标题:《如何实现数据库实时计算,实时数据库设计 》




 滇ICP备2023011059号-1
滇ICP备2023011059号-1